
本篇会加入个人的所谓鱼式疯言
❤️❤️❤️鱼式疯言:❤️❤️❤️此疯言非彼疯言
而是理解过并总结出来通俗易懂的大白话,
小编会尽可能的在每个概念后插入鱼式疯言,帮助大家理解的.
🤭🤭🤭可能说的不是那么严谨.但小编初心是能让更多人能接受我们这个概念 !!!


-
HashSet
-
HashMap
前言
在探索Java集合框架的丰富世界时,我们不可避免地会遇到两个至关重要的成员:HashMap和HashSet。这两个组件虽然在功能上有着明显的交集,但它们在内部实现、性能表现以及使用场景上却有着显著的差异。本文将深入探讨HashMap与HashSet的内部机制,比较它们的性能特点,并指导读者如何在实际开发中做出恰当的选择
一. HashSet
1. set 的初识
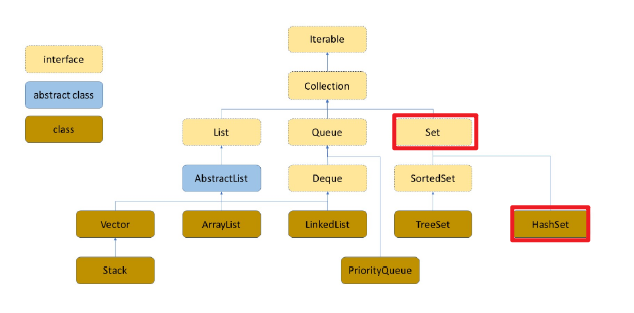
对于
set来说, 继承自Collection的类, 可以由SortedSet和TreeSet和HashSet来实现。对于
set 本身来说, 只 存储 key 的值 , 并不存values, 并且这个 key是唯一的, 且 不可修改的 。
在本篇文章中将重点讲解 HashSet 来实现 Set 类 。
鱼式疯言
set 本身的含义有: 设置 , 集合 。
在 Java集合框架 中,
set的含义就表示 集合 。集合中的关键码
(key)就有 两大特性 : 1.无序性2.唯一性
2. set 的常见方法使用

如上图, 小编介绍几种常见的方法, 足够我们平常 面试和刷算法题 中使用了
如果还想了解的小伙伴可以 参考下面的官方文档 哦 💕 💕 💕 💕
3. 代码演示
```bash
class Test1{
public static void main(String[] args) {
Set set = new HashSet<>();
set.add(1);
set.add(2);
set.add(3);
set.add(4);
set.add(5);
// 使用迭代器 接收
Iterator iterator = set.iterator();
// 输出迭代器
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
// 判断 4 是否存在
if(set.contains(4)) {
System.out.println("删除前"+ 4 + "存在!");
} else {
System.out.println("删除后"+ 4 + "不存在!");
}
// 得到key 的个数
System.out.println(set.size());
set.remove(4);
if(set.contains(4)) {
System.out.println("删除后" + 4 + "存在!");
} else {
System.out.println("删除后" + 4 + "不存在!");
}
}
}
```
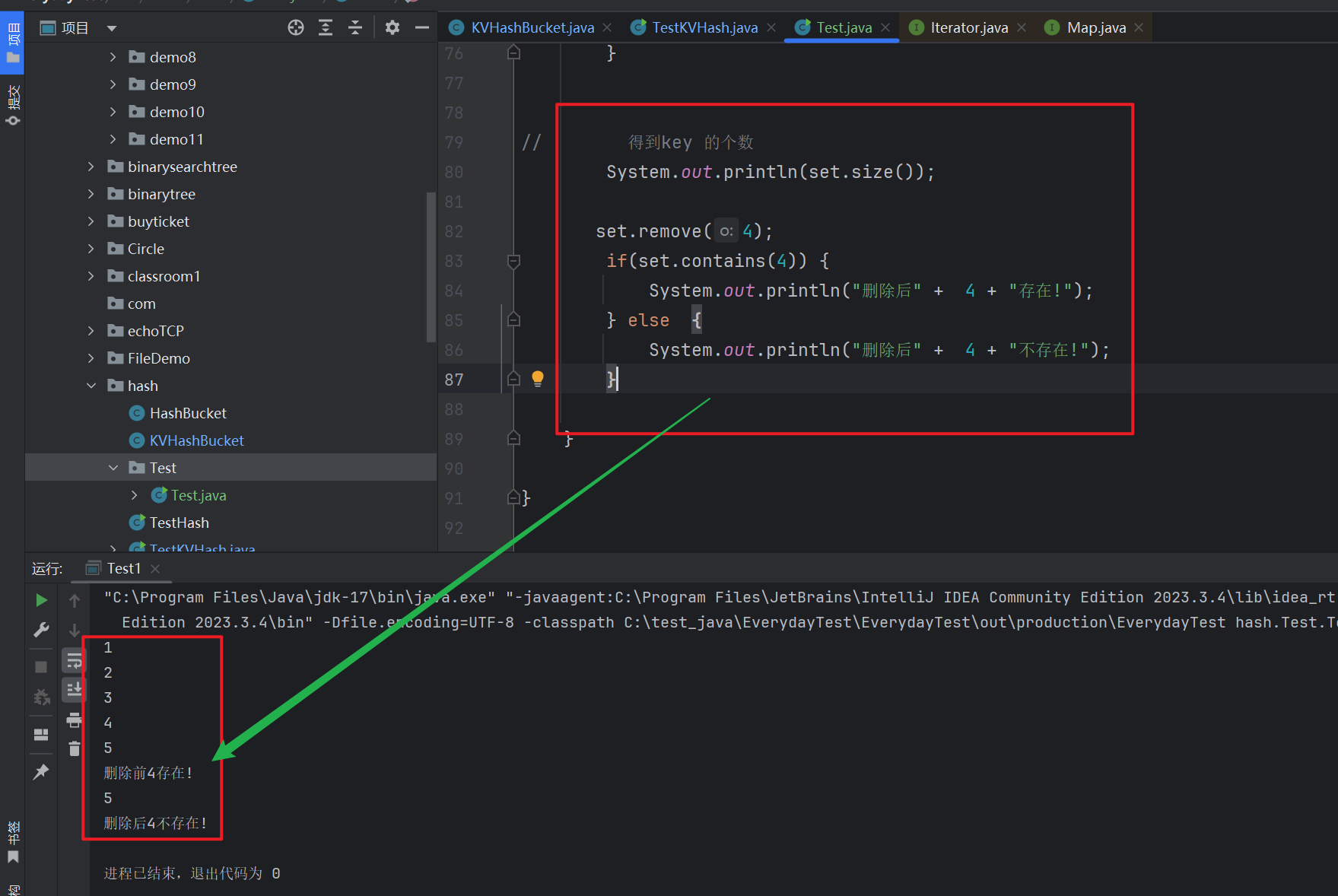
-
add()添加了 key 值 , 如果set中存在则 添加失败 -
contains()检查 是否存在该key -
remove()删除某个key -
size()得到key 的个数 -
iterator 迭代器, 用来得到全部的key的一个 整体的迭代器
鱼式疯言
补充说明
对于
set的用法主要是用于判断是否 有重复元素 , 并且进行去重操作。 并且用HashSet实现, 时间复杂度 可以达到O(1)。对于
HashSet 实现的 set 接口, 是可以进行 插入 null 的 。
二. HashMap
1. Map 的初识
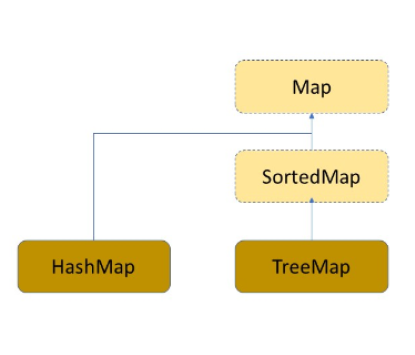
对于
Map而已, 该接口 不继承Collection 接口 , 可有 HashMap 或 TreeMap 实现,并且
Map中存储的是 一对K和 V 的键值对 。其中 K 是 关键码(key) 用来 作为标识 , 是用来转化为
哈希地址的 索引标识 , 是 唯一的 , 不可更改 , 不能重复 。而 V 是 值 (value) , 用来存储具体需要 存储的数据 。
上面的解释, 可能小伙伴们还不是很能理解
不妨回忆下我们上篇文章的 哈希表的建立
其中数组的下标就可以作为
索引值, 而key 就可以通过 某种哈希函数 来转化为 数组的下标 。而
value就可以刚好对应数组下标位置所 对应的值 。
鱼式疯言
小知识 :
对于 HashMap 实现的Map 来说, 键值对都是可以置为 null 的。
2. Map.Entry
Map.Entry 是一种专门 存放键值对的一种类型 , 并且是 Map 的静态方法 , 可以 不需要对象调用 。
其实有下面三种方法 ,小编在这里就展示 前两个 。
下面我们来看看其演示过程
```java
public static void main(String[] args) {
// entry
Map.Entry entry = Map.entry("s","t");
System.out.println(entry.getValue());
System.out.println(entry.getKey());
}
```
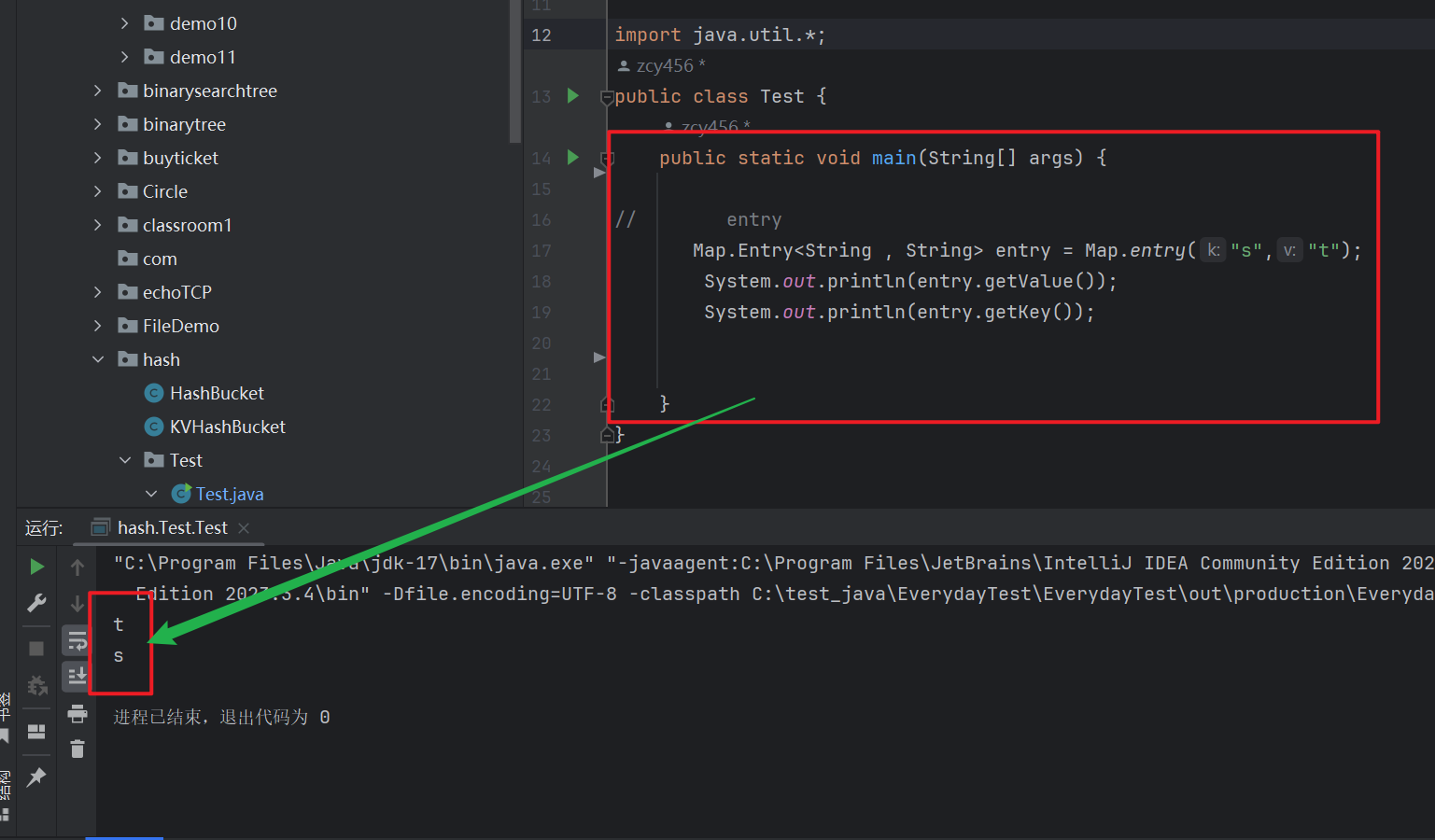
如上图
其中
s就代表 key 的关键码,可以用getValue获取到而
t就表示 value 的关键码 , 可以用getKey来 获取到。
这个类型 其实用的不多, 小伙伴们只需要了解一下即可。
鱼式疯言
补充说明 :
虽然小编上面说明有提供了 修改Value 的方法, 但是并 没有提供 修改
Key的方法。
所以对于key来说, 是 不可修改的 。
3. Map 的常见方法使用
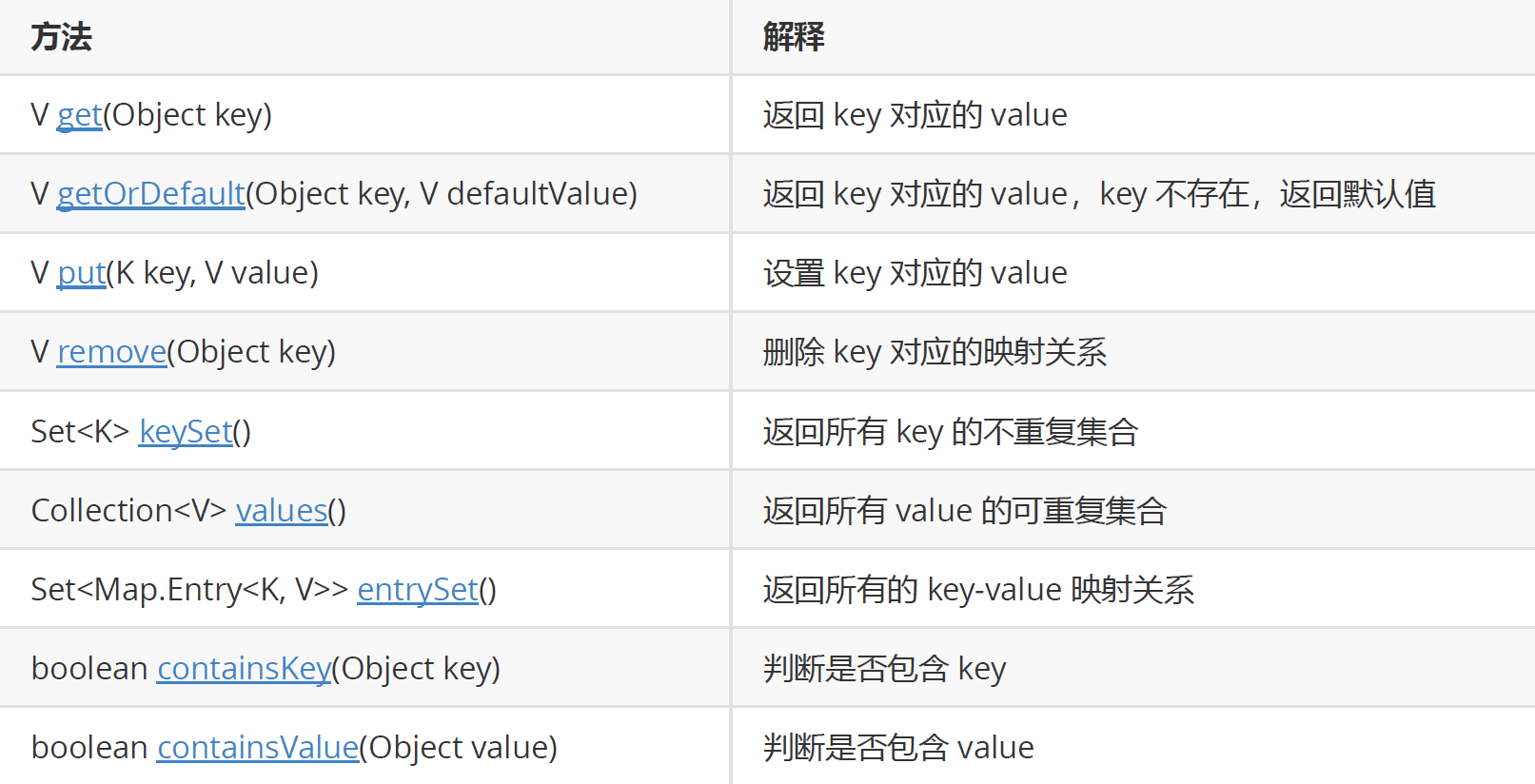
对于上述的方法来说, get (), getOrDefault() , put() , remove(), keySet() , values() 等…
以上这些方法, 小编都会一一演示。
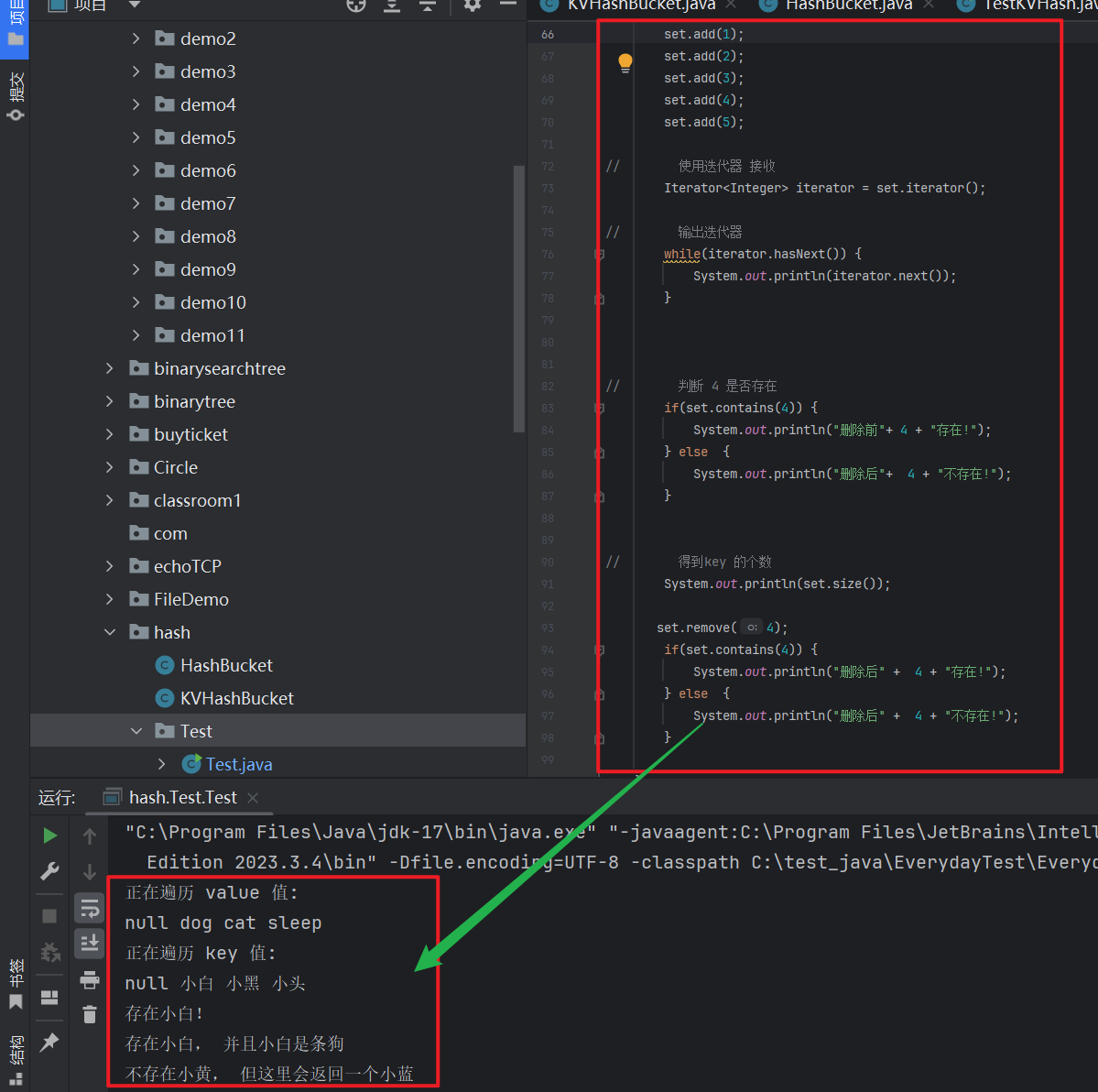
4. 代码演示
```java
import java.util.*;
public class Test {
public static void main(String[] args) {
// 实例化一个 map 对象
Map map = new HashMap<>();
map.put("小白", "dog");
map.put("小黑", "cat");
map.put("小头", "sleep");
map.put(null, null);
System.out.println("正在遍历 value 值: ");
// 使用 values 演示得到的所有的value 的结果
Collection strings = map.values();
for(String strings1 : strings) {
System.out.print(strings1 + " ");
}
System.out.println();
// 使用 keyset 演示所以得到的 key 的结果
System.out.println("正在遍历 key 值: ");
Set strings1 = map.keySet();
for (String str : strings1) {
System.out.print(str+ " ");
}
System.out.println();
// 判断map 是否存在 某个特定的 value 和 key
if(map.containsKey("小白")) {
System.out.println("存在小白!");
if (map.containsValue("dog")) {
System.out.println("存在小白, 并且小白是条狗");
} else {
System.out.println("存在小白, 但是小白不是条狗!");
}
}
// 获取小黄的value , 如果没有就会返回 defaultValue 的特定的value
String ret = map.getOrDefault("小黄", "不存在小黄,
但这里会返回一个小蓝");
System.out.println(ret);
}
}
```
-
通过
get()其中参数列表中填入的 key 的值, 然后 调用 get() 之后 , 就会得到该key所对应的 value 值 。 -
getOrvalue()如果有key就返回 对应的value 值 , 如果没有就 返回后面那个参数的结果 。 -
put()就相等于 插入元素 , 不仅要插入 key , 也要 插入key 所对应的value 。 从而得到 两者相关联 , 一样对应的关系 的作用。 -
remove() , 是直接删除 key , 并且 一旦删除 key , 那么 对应的value 也会被删除。
-
keyset() , 这个方法的作用就在于 获取map 中所有的key 值 , 并且用前面讲解过的
Set来接收。 -
values()这个方法的含义就在于 获取map 中所有的 value值 , 返回值是一个Collection来接收。 -
containsKey(), 用于判断指定的key 是否存在 -
containsValue(), 用于判断指定的 value 是否存在 。
鱼式疯言
补充说明:
-
对于map 来说, key 是不可重复的 , 但是
value 是可以重复,并且是可以修改的, 如果 一定要修改key 的值 , 就需要把 原先的key 删除 , 然后添加一个新的key。 -
由于
key 是不可重复的, 当我们返回 key 的集合 时, 就可以用set 来接收 ,因为set 的最大功能就是对元素 进行去重 , 达到每一个 关键码都是唯一性 的 -
由于 value 是可以重复的 , 当我们返回
value的集合时 , 不可以用 set 来接收 , 一般用Collection 来接收 。 -
综上所得, 对于
set的而言, 如果涉及到 单个元素的去重操作一般我们使用 set ,
但如果有 两种关联属性 的话, 我们一般用 map 来 建立键值对进行操作 。
三. 哈希桶实现哈希表
哈希桶的本质就是当出现哈希冲突时, 利用 链表把新的关键码(key) 插入 到 原有的 key 的后面 , 把 一个大集合转化为一个小集合 来使用。
如果对这个概念还很模糊的小伙伴可以参考小编的上一篇文章哦 💕 💕 💕 💕
1. 哈希桶的代码展示
```java
package hash;
public class KVHashBucket {
// 存放链表数组
Node[]array;
// 实际元素个数
int useSize;
private static final int DEFAULTSIZE=10;
// 定义一个内部类为节点
static class Node {
V val;
Node next;
K key;
public Node(K key,V val) {
this.key=key;
this.val = val;
}
}
public KVHashBucket() {
array= (Node[]) new Node[DEFAULTSIZE];
}
/**
* 插入方法
* @param val 需要插入的数据
*/
void put(K key,V val) {
// 判断是否满
if (isFull()) {
insertFunc2(key,val);
return;
}
insertFunc1(key,val);
}
/**
* 未满时普通插入
* @param val 需要插入的数据
*/
private void insertFunc1(K key,V val) {
int sz=array.length;
int k=key.hashCode();
int index= k % sz;
// 如果出现 key 重复 就修改 val 值
Node cur=array[index];
while (cur != null) {
if (cur.key == key) {
cur.val=val;
return;
}
cur=cur.next;
}
Node node=new Node(key,val);
node.next=array[index];
array[index]=node;
useSize++;
}
/**
* 扩容方法
* @param val 插入数据
* 先扩容一个新数组
* 然后把旧数组整合放入新数组
* 最后旧数组成为新数组
*/
private void insertFunc2(K key ,V val) {
Node cur=null;
Node[] newArray= (Node[]) new Node[2 * array.length];
int newLength = 2 * array.length;
for (int i = 0; i < array.length; i++) {
cur=array[i];
while (cur != null) {
K m = cur.key;
// 先让 node 记住 cur 的下个节点
Node node = cur.next;
int k=m.hashCode();
int index= k % newLength;
cur.next = newArray[index];
newArray[index] = cur;
cur=node;
}
}
Node til=new Node(key,val);
int k=key.hashCode();
int index=k%newLength;
// 如果出现 key 重复 就修改 val 值
Node curN=array[index];
while (curN != null) {
if (curN.key == key) {
curN.val=val;
return;
}
curN=curN.next;
}
til.next=newArray[index];
newArray[index]=til;
useSize++;
array=newArray;
}
/**
* 查找该节点
* @param key 需要查找的数据
* @return 返回该数据的节点
*/
public V get(K key) {
if (isEmpty()) return null;
int k=key.hashCode();
int index = k % array.length;
Node cur=array[index];
while (cur != null) {
if (cur.key.equals(key)) {
return cur.val;
}
cur=cur.next;
}
return null;
}
/**
* 查找是否该节点
* @param key 需要查找的数据
* @return 返回是否找到
*/
public boolean contains(K key) {
if (isEmpty()) return false;
int k=key.hashCode();
int index=k % array.length;
Node cur=array[index];
while (cur != null) {
if (cur.val.equals(key)) {
return true;
}
cur=cur.next;
}
return false;
}
public boolean remove(K key) {
if (isEmpty()) return false;
int k=key.hashCode();
int index = k % array.length;
Node cur = array[index];
Node node = cur;
if (cur.key==key) {
array[index]=cur.next;
return true;
}
while (cur != null) {
if (cur.key.equals(key)) {
node.next = cur.next;
useSize--;
return true;
}
node = cur;
cur = cur.next;
}
return false;
}
/**
* 判断是否满
* @return 返回结果
*/
private boolean isFull() {
return (useSize*1.0/array.length) >= 0.75;
}
/**
* 判断是否为空
* @return 返回结果
*/
private boolean isEmpty() {
return useSize==0;
}
}
```
```bash
public class TestKVHash {
public static void main(String[] args) {
KVHashBucket kvhb=new KVHashBucket<>();
kvhb.put("钟大帅哥","喜欢美女!");
kvhb.put("郭大男神","喜欢拉比!");
kvhb.put("刘大少爷","喜欢花钱!");
}
}
```
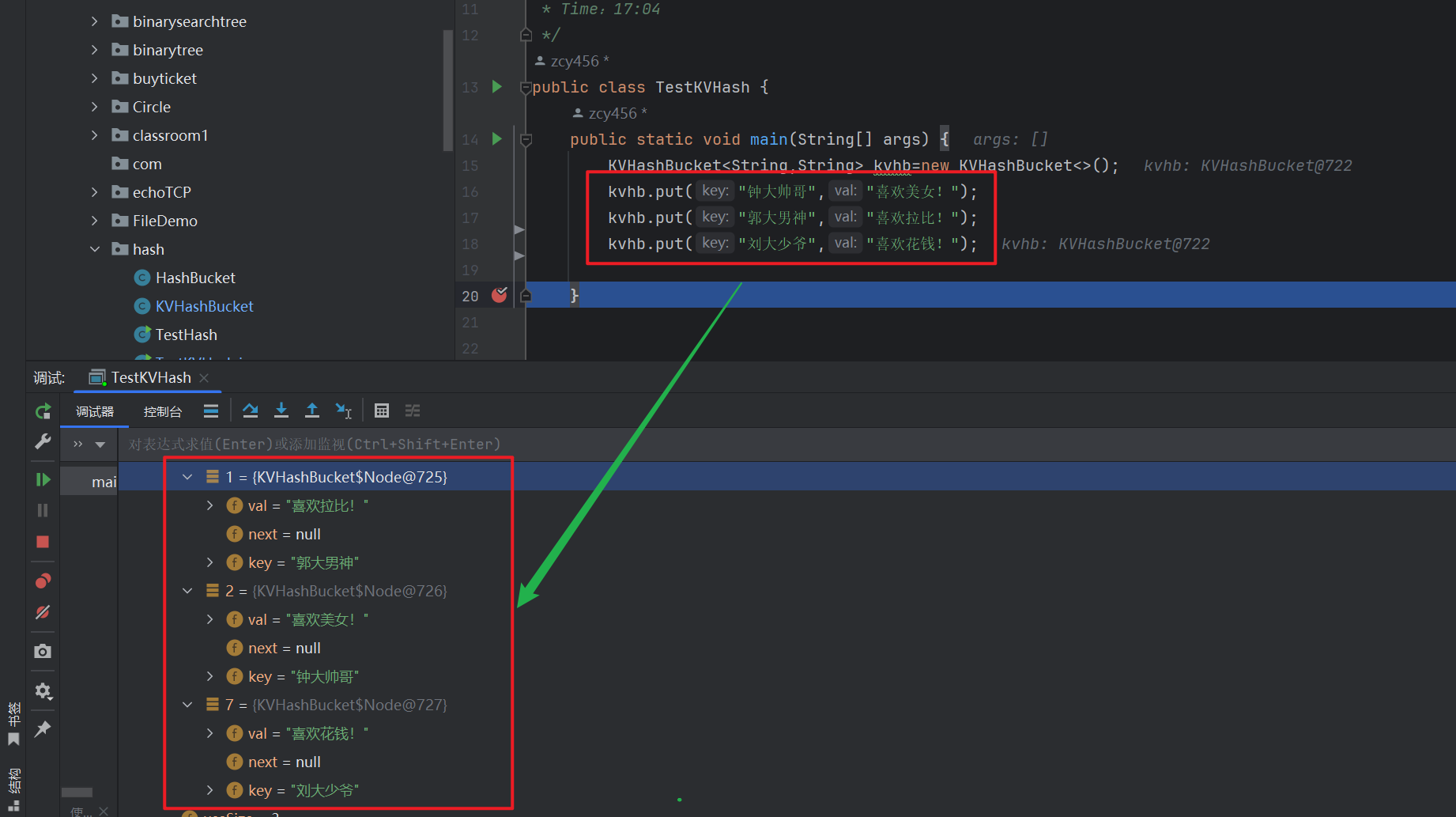
具体的实现 流程三部曲 :
-
首先创建一个
Node 类的节点 -
然后创建一个 Node类型的数组来存储
-
对利用 key 进行hashcode寻找到索引值, 根据索引操作链表 进行 增删查改 。
鱼式疯言
上述流程,小编只 强调三点
-
负载因子一旦达到
0.75就相当于 满了, 就需要 扩容 -
扩容的过程中, 需要将 旧表转移到新表 中,不可以只是扩容而不转移, 否则数据会集中在原数组中, 而不会分散到新扩扩容的数组空间中。
-
如果添加时,遇到 相同的key 时, 只需要修改 原先 value 成 现有的 value , key 无须变动 即可。
其他小编认为问题不大,小伙伴们可以自己先 操练操练 哦, 如果有不清楚的地方, 欢迎评论区留言哦 。💖 💖 💖
总结
-
hashset: 对于Hashset 来说主要是运用 Hashset 实现Set的相关的方法 来达到判断数据是否重复和 进行去重操作的目的 。 -
HashMap : 对于
hashMap实现 Map 接口, 达到对于键值对之间的关联, 已经对于 键的唯一性 所包含 值的可重复性 查找操作。 -
哈希桶的实现: 利用数组和泛型来理解 哈希函数的底层实现 , 并注意实现过程中
负载因子的更新以及背后的细节。
如果觉得小编写的还不错的咱可支持 三连 下 (定有回访哦) , 不妥当的咱请评论区 指正
希望我的文章能给各位宝子们带来哪怕一点点的收获就是 小编创作 的最大 动力 💖 💖 💖

文章整理自互联网,只做测试使用。发布者:Lomu,转转请注明出处:https://www.it1024doc.com/6771.html