
*

文章目录
一、非递归版快排
1.使用栈实现非递归版快排
在学习非递归版快排前,建议大家先学习递归版的快排,否则非递归版的快排将很难理解,这里附上本人写的快排的博客解析:【初阶数据结构与算法】八大排序算法之交换排序(冒泡排序,快速排序—hoare、挖坑法、lomuto双指针3种版本)
接下来我们来学习如何使用栈这个数据结构帮我们实现快排,首先我们都知道快排是通过递归实现的,那么问题来了,为什么栈就可以帮我们模拟递归的行为
这就不得不提到递归的本质了,递归是通过函数自己对自己的调用,在内存的栈区开辟新的函数栈帧,执行同样的代码实现递归,此时我们要发现一个重点,就是递归的本质是通过在栈区开辟函数栈帧实现
而栈区的压栈方式与我们数据结构中的压栈类似,所以我们才能通过栈这个数据结构来模拟递归调用的行为,只要理解到这一点,后面的内容将会好懂得多
接着我们来正式实现非递归版的快排,首先我们需要一个栈作为辅助,可以将之前写过的栈导入到当前文件夹进行添加,栈在非递归快排中的任务就是存储下标
因为我们递归划分数组不是真的把它们分开了,而是通过给定左右范围的下标来访问不同区域,以此达到划分数组的效果,所以快排递归最重要的信息是下标,只要我们能将下标保存并能够以类似于递归的方式使用,我们就可以不使用递归实现快排
而栈就可以起到这样的效果,我们将指定数组序列的左右下标存入栈中,为了我们取出来是左右的顺序,我们在入栈时要将右下标先入栈,再入栈左下标,如下:
```c
//非递归版快排
void NonRQuickSort1(int* arr, int left, int right)
{
ST st;
STInit(&st);
STPush(&st, right);
STPush(&st, left);
STDestroy(&st);
```
这样我们就可以保证我们取出对应下标时先取出左下标,再取出右下标,接着我们就创建一个循环,只要栈不为空,我们就进入循环取出对应的左右下标,简单进行一下判断,如果左右下标不符合要求就跳过后面的处理,如果左右下标没有问题就使用快排子函数对这段区间进行处理,最后返回处理好的基准值下标,如下:
```c
while (!STEmpty(&st))
{
//取出区间的下标
int left = STTop(&st);
STPop(&st);
int right = STTop(&st);
STPop(&st);
//如果取出的下标不需要处理就直接使用continue跳过
if (left >= right) continue;
int keyi = _QuickSort(arr, left, right);
}
```
接着我们就根据返回的基准值的下标对当前的区间进行划分,然后将这些划分后的下标入栈,要注意的是要从右往左将下标入栈,否则到时候取下标的时候可能左右下标相反的,如下:
```c
//非递归版快排
void NonRQuickSort1(int* arr, int left, int right)
{
ST st;
STInit(&st);
STPush(&st, right);
STPush(&st, left);
while (!STEmpty(&st))
{
int left = STTop(&st);
STPop(&st);
int right = STTop(&st);
STPop(&st);
if (left >= right) continue;
int keyi = _QuickSort(arr, left, right);
//[left, keyi - 1] [keyi + 1, right]
STPush(&st, right);
STPush(&st, keyi + 1);
STPush(&st, keyi - 1);
STPush(&st, left);
}
STDestroy(&st);
}
```
这样我们非递归版本的快排就完成了,如果对比递归版的快排的话,可以发现差别都不大,只是使用栈模拟了递归的行为,其实它还可以进行优化,这个我们后面再讲,现在我们先运行一下代码,看看有没有问题: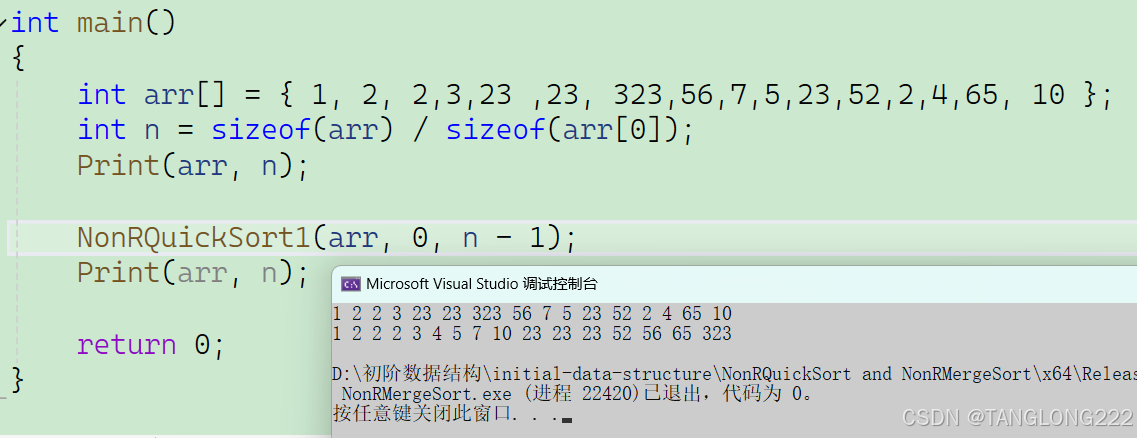
可以看到代码没有问题,接着我们来优化一下上面的代码,在上面的非递归快排代码中,我们是将所有区间都入栈,没有判断它们是否越界等等情况,而是在取出它们之后进行判断,很明显这样入栈没用的区间非常耗费资源
所以我们可以对它进行优化,在入栈之前我们可以判断一下新的左右区间,区间如下:
```c
[left, keyi - 1] [keyi + 1, right]
```
如果left大于或等于keyi - 1,说明此时这个区间只有一个元素,或者根本不存在这个区间,r如果right小于或等于keyi + 1,说明这个区间也只有一个元素,或者这个区间根本不存在,所以我们在入栈前可以做如下判断:
```c
//right满足条件才让右序列的左右下标入栈
if (right > keyi + 1)
{
STPush(&st, right);
STPush(&st, keyi + 1);
}
//left满足条件才让左序列的左右下标入栈
if(left < keyi - 1)
{
STPush(&st, keyi - 1);
STPush(&st, left);
}
```
这样我们使用了一个简单的条件判断就可以去掉许多无用的入栈、出栈操作,优化后的代码如下:
```c
//非递归版快排
void NonRQuickSort1(int* arr, int left, int right)
{
ST st;
STInit(&st);
STPush(&st, right);
STPush(&st, left);
while (!STEmpty(&st))
{
int left = STTop(&st);
STPop(&st);
int right = STTop(&st);
STPop(&st);
//if (left >= right) continue;
int keyi = _QuickSort(arr, left, right);
//[left, keyi - 1] [keyi + 1, right]
if (right > keyi + 1)
{
STPush(&st, right);
STPush(&st, keyi + 1);
}
if(left < keyi - 1)
{
STPush(&st, keyi - 1);
STPush(&st, left);
}
}
STDestroy(&st);
}
```
我们来测试一下这段代码: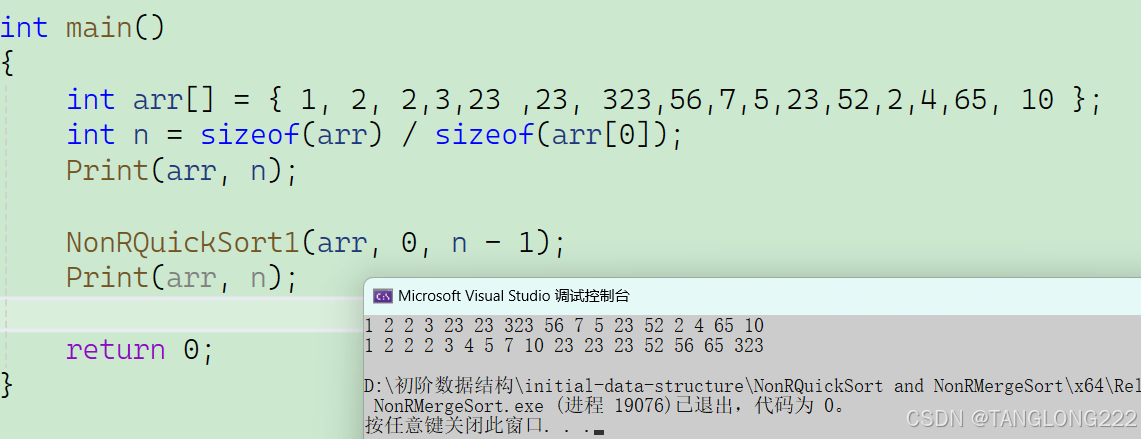
可以看到代码没有问题,这就是使用栈实现非递归版快排的所有过程啦,接下来我们开始学习使用队列实现非递归版快排
2.使用队列实现非递归版快排
刚刚的非递归快排就是利用栈模拟递归,因为递归的本质就是在栈区里面开辟新的函数栈帧,这个过程和我们入栈操作类似,所以我们才能使用栈实现非递归快排
那么队列又为什么可以实现非递归快排呢?这个时候我们就要换个角度来看待快排了,我们要以二叉树的角度来理解快排,快排就类似于二叉树中的前序遍历
就是将整个数组看作一颗二叉树的根,先通过子函数处理整个数组,然后再通过返回的基准值下标进行划分左右区间,然后再递归处理左右区间,跟我们的前序遍历相似
那么这时候我们再联系队列可以想到什么呢?是不是就可以想到我们的层序遍历,由于快排的左右区间一旦划分就互不影响,所以我们可以使用层序遍历的思想,将划分出来的左右区间依次进行处理,层序遍历结束,我们的快排也就结束了
所以我们的队列版快排就是模仿层序遍历的过程,但是代码形式其实和栈一模一样,只是将用栈的地方全部换成了队列,但是我们要知道为什么可以使用队列实现非递归的快排,接下来我们就来按照思路写代码,如下:
```c
//非递归版快排(使用队列实现)
void QuickSortNonR2(int* arr, int left, int right)
{
Queue q;
QueueInit(&q);
QueuePush(&q, left);
QueuePush(&q, right);
while (!QueueEmpty(&q))
{
int left = QueueFront(&q);
QueuePop(&q);
int right = QueueFront(&q);
QueuePop(&q);
int keyi = _QuickSort(arr, left, right);
//[left, keyi - 1] [keyi + 1, right]
if (left < keyi - 1)
{
QueuePush(&q, left);
QueuePush(&q, keyi - 1);
}
if (right > keyi + 1)
{
QueuePush(&q, keyi + 1);
QueuePush(&q, right);
}
}
QueueDestroy(&q);
}
```
我们来测试一下队列实现的非递归排序能否帮我们完成排序工作,如下:
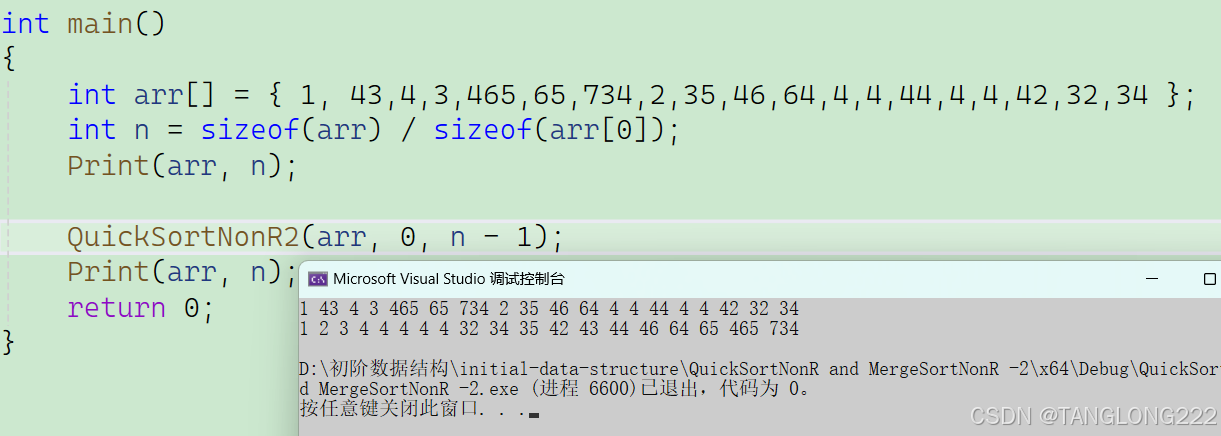
可以看到代码没有问题,接下来我们继续学习非递归版的归并排序
二、非递归版归并排序
在学习非递归版归并排序之前,希望大家先要搞懂递归的归并排序的实现原理,否则学习非递归版的归并排序将会很痛苦,这是本人曾写过的一篇归并排序的博客,如果还没有学过归并排序可以看看:【初阶数据结构与算法】八大排序算法之归并排序与非比较排序(计数排序)
1.非递归版归并排序的实现
如果说快排的形式类似于前序遍历,那么归并排序的形式就类似于后序遍历,那么我们能否使用栈或者是队列来实现非递归版的归并排序呢?
结论是不可以,那么这是为什么呢?因为后序遍历会让左子树递归到最深处,然后对左子树处理后进行返回,然后右子树递归到最深处处理后返回,最后我们处理根的时候,是需要左右子树的信息的
但是如果使用栈的话就模拟不出这个效果,因为栈里面存储的是下标,这个序列的区间下标一用完我们就会将它pop掉,导致我们在最后处理根的时候拿不到左右子树的信息,这就是不能使用栈实现归并的原因
其实大致总结一下,如果递归的形式像前序遍历,那么我们才能使用栈来模拟它的行为,如果类似于中序和后序遍历就不行,根本原因还是前序遍历会先处理根,不需要左右子树的信息,而中序和后序遍历时,处理根就会需要左子树或者左右子树的信息,而栈只能模拟先处理根的情况
那么我们怎么才能实现非递归版的归并排序呢?这就要求我们透过归并排序看清它的本质了,它的本质就是对数组进行分组,然后两两一组进行排序,最后进行合并,如图: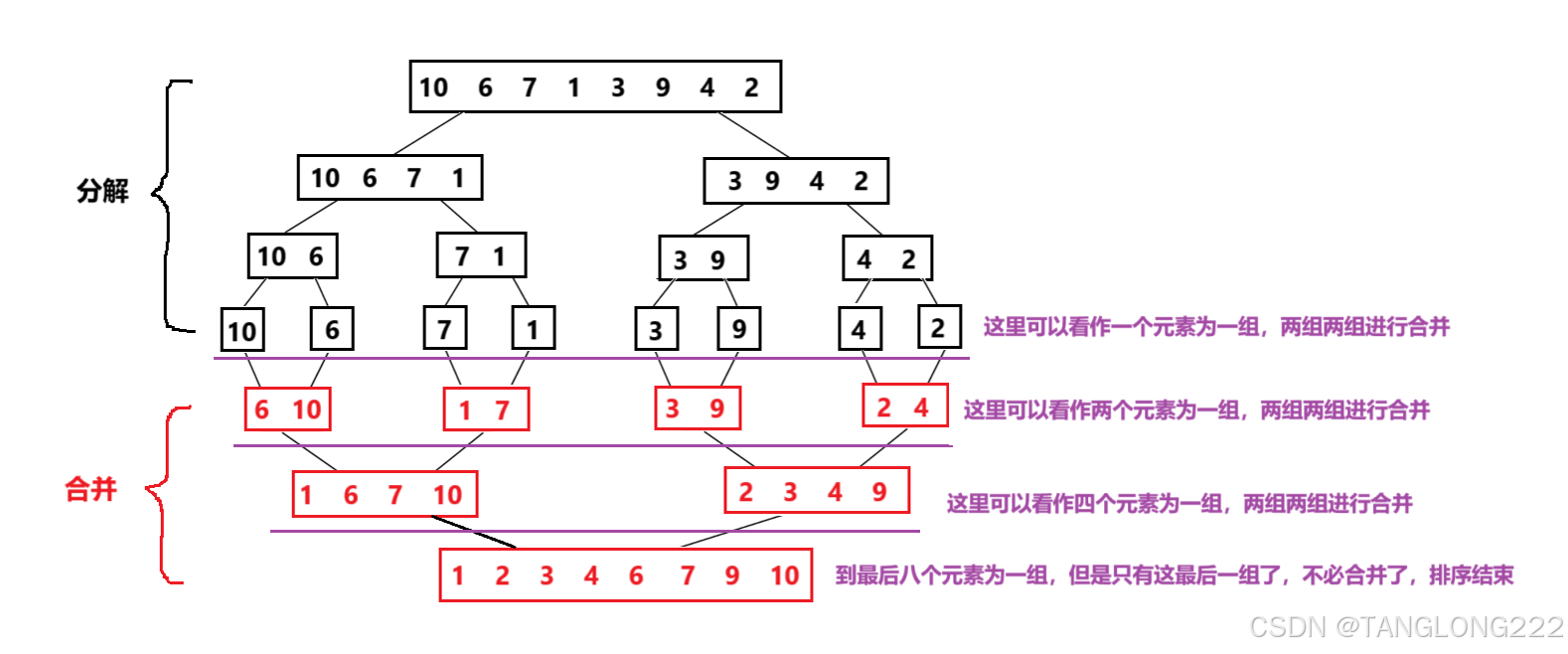
所以我们就可以写代码来模拟这个过程,首先将数组的一个元素划分为一组,然后两组两组进行合并,只不过将数组两组两组合并完之后,我们要将数组重新进行分组,变成两个元素划分为一组再进行合并,反复进行上面的操作,直到数组不能再划分
所以我们首先定义一个变量gap来表示一个组有多少个元素,默认情况下为1,然后我们就开始两组两组进行合并,合并的逻辑和递归版的归并排序合并逻辑相似,这里不再赘述
当我们将以gap个元素为一组的情况,两组两组合并完之后,就让gap * 2来调整每组元素的个数,用新的gap来划分数组,然后又两组两组对数组进行合并,直到gap大于或者等于n
上面也就是整个非递归版归并排序的大致逻辑了,还有一些重要的细节我们稍后再说,我们先将上面说的逻辑大致实现一下,如下:
```c
//非递归版归并排序
void MergeSortNonR(int* arr, int n)
{
int* tmp = (int*)malloc(n * sizeof(n));
if (tmp == NULL)
{
perror("malloc");
return;
}
//默认1个元素为一组
int gap = 1;
while (gap < n)
{
//接下两两组两组对数组进行合并,一次循环就合并两组
//所以要注意i每次要跳过两组,也就是i += 2 * gap
for (int i = 0; i < n; i += 2 * gap)
{
//排序两组的逻辑,和递归版归并排序合并的逻辑相同
//注意下面begin1和end1的取值
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
int j = begin1;
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] < arr[begin2])
tmp[j++] = arr[begin1++];
else
tmp[j++] = arr[begin2++];
}
while (begin1 <= end1)
{
tmp[j++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = arr[begin2++];
}
for (int j = i; j <= end2; j++)
{
arr[j] = tmp[j];
}
}
//当我们将以gap个元素为一组的情况,两组两组合并完之后
//就让gap * 2来调整每组元素的个数,用新的gap来划分数组
gap *= 2;
}
}
```
上面就是非递归归并排序的大致逻辑,但是如果我们直接使用上面的代码进行排序时就会发现它有问题,因为上面的代码对数组进行分组时,gap都是2的倍数,如1, 2, 4等等,如果我们数组元素的个数是奇数就会越界
所以接下来的细节问题就是如何处理越界问题,首先我们来分析begin1、end1,、begin2以及end2这几个变量哪些可能越界,结论就是begin1不会越界,其它3个变量都可能越界,因为begin1就是i,只要进入循环i就不会越界
如果i越界,就不会进入循环,begin1也就不会存在,只要进入了循环begin1,就会将i赋值给begin1,所以begin1就不会越界,其它三个变量则都可能越界,我们接下来一一进行分析,首先我们来画图将这些情况画出来,如下: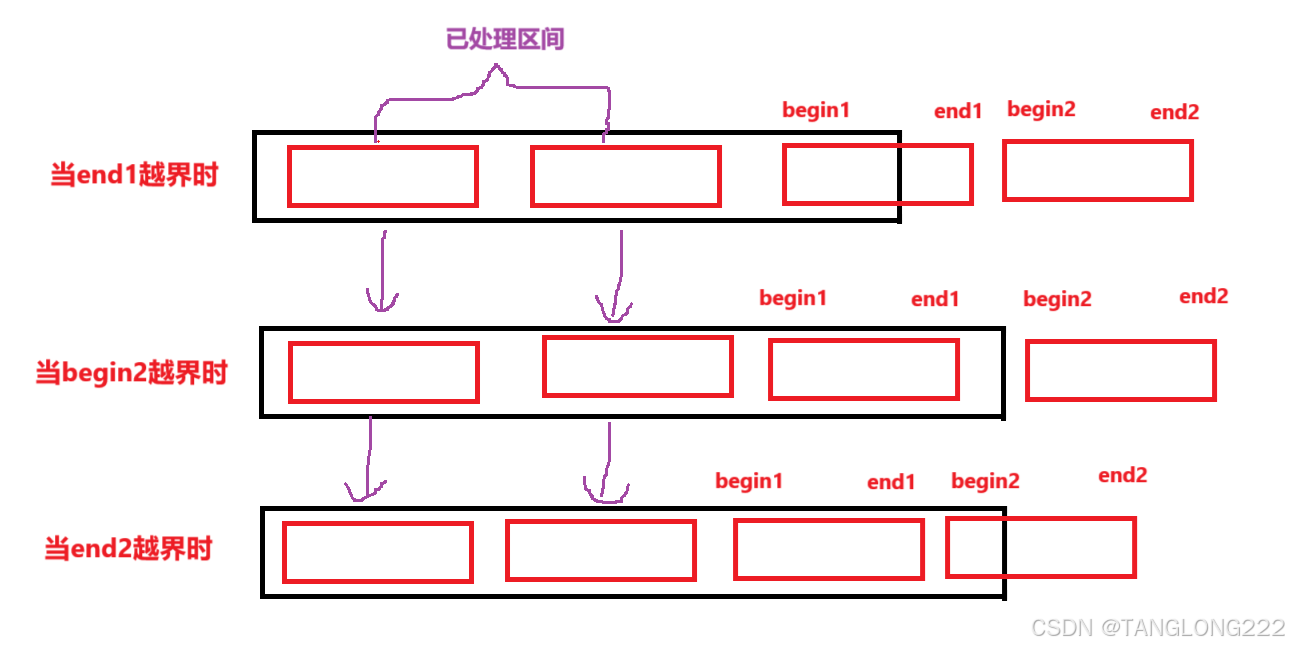
接着我们一一来处理一下这些边界情况,当end1越界时,说明begin2这个组全部越界了,那么这两组就不会进行合并,我们直接break掉就可以
当begin2越界时,也说明了后面这个组全部越界了,不会进行合并,直接break掉就可以了,当end2越界时,很明显前面begin2到数组最后还有一部分可以合并的区间,所以这时我们不能直接break,可以直接将end2改成n - 1,这样就能正常完成合并
然后我们稍加观察一下,其实end1和begin2越界这两种情况可以写到一起,因为它们都是因为后面这个组全部越界了,导致不需要再合并直接break,所以可以直接写到一起,接下来我们就将刚刚讲到的细节补到上面的代码中,写出一个完整的非递归归并排序,如下:
```c
//非递归版归并排序
void MergeSortNonR(int* arr, int n)
{
int* tmp = (int*)malloc(n * sizeof(n));
if (tmp == NULL)
{
perror("malloc");
return;
}
//默认1个元素为一组
int gap = 1;
while (gap < n)
{
//接下两两组两组对数组进行合并,一次循环就合并两组
//所以要注意i每次要跳过两组,也就是i += 2 * gap
for (int i = 0; i < n; i += 2 * gap)
{
//排序两组的逻辑,和递归版归并排序合并的逻辑相同
//注意下面begin1和end1的取值
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//如果end1或者begin2越界,说明后面这个组整体越界
//不需要进行合并,直接break掉
if (end1 >= n || begin2 >= n)
{
break;
}
//如果只是end2越界的话,就将end2改成n - 1
else if (end2 >= n)
{
end2 = n - 1;
}
int j = begin1;
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] < arr[begin2])
tmp[j++] = arr[begin1++];
else
tmp[j++] = arr[begin2++];
}
while (begin1 <= end1)
{
tmp[j++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = arr[begin2++];
}
for (int j = i; j <= end2; j++)
{
arr[j] = tmp[j];
}
}
//当我们将以gap个元素为一组的情况,两组两组合并完之后
//就让gap * 2来调整每组元素的个数,用新的gap来划分数组
gap *= 2;
}
}
```
接下来我们来测试一下非递归的归并排序: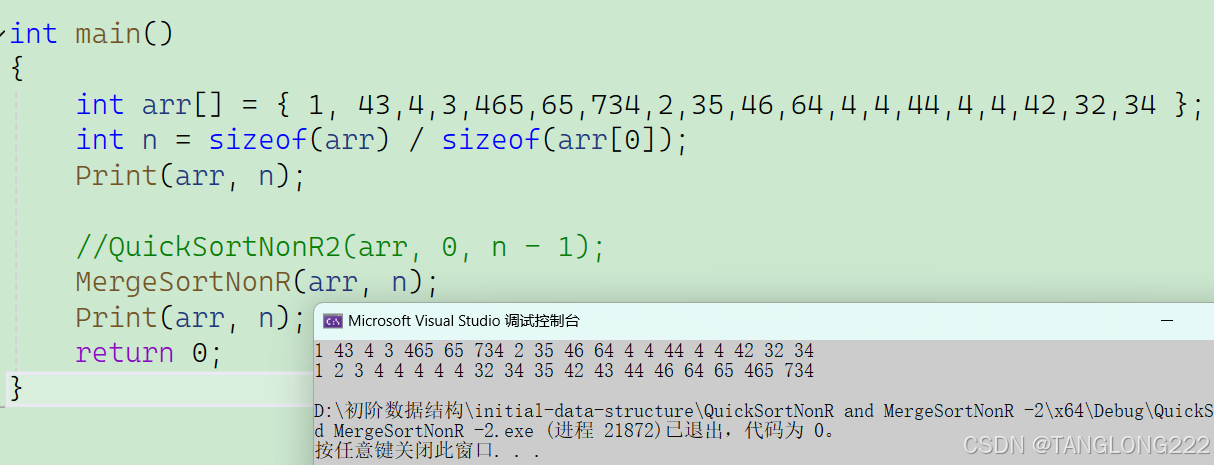
可以看到代码帮我们完成了排序工作
那么今天非递归排序就介绍到这里,如果有什么问题欢迎私信我,下一篇我们总结一下排序算法,接着就可以进入C++篇章了,敬请期待吧!
bye~
文章整理自互联网,只做测试使用。发布者:Lomu,转转请注明出处:https://www.it1024doc.com/5685.html