
拼写纠正系列
NLP 开源项目
以下是一些精选的NLP开源项目,它们在拼写检测和纠正方面表现出色:
- nlp-hanzi-similar:汉字相似度计算库
- word-checker:中英文拼写检测工具
- pinyin:汉字转拼音工具
- opencc4j:繁简体转换库
- sensitive-word:敏感词检测工具
前言
大家好,我是老马。
本文将分享一些开源项目和文章,它们在自然语言处理(NLP)领域,特别是在拼写检测和纠正方面,有着出色的表现和深入的解析。
个人感受
在探索贝叶斯方法的过程中,我发现其实实现起来相当直接。核心步骤包括识别拼写错误的单词,然后计算编辑距离在2以内的候选词,评估它们出现的概率,并据此进行排序。
我的实现方法与此类似,不过我提前优化了词典的频率处理。尽管如此,我认为还有进一步优化的空间,比如利用n-gram模型来提高准确性。
例如,如果一个单词的前半部分正确,而后半部分出错,我们可以使用2-gram模型来推断正确的后半部分。
贝叶斯公式
贝叶斯定理
贝叶斯定理是由英国数学家贝叶斯(Thomas Bayes 1702-1761)提出的,它描述了两个条件概率之间的关系,例如P(A|B)和P(B|A)。根据乘法法则,我们可以推导出贝叶斯定理:
P(A|B) = P(A)·P(B|A) / P(B)
这个公式也可以变形为:
P(B|A) = P(A)·P(A|) / P(A)
拼写错误的定义
拼写纠错(Spelling Correction),也称为拼写检查(Spelling Checker),广泛应用于文本编辑、输入法和搜索引擎等领域。它通常包括两个子任务:
拼写错误检测
- Non-word Errors:错误拼写形成的词本身不合法,例如将"giraffe"错误拼写为"graffe"。
- Real-word Errors:错误拼写形成的词仍然是合法的,例如将"there"错误拼写为"three"(形近),将"peace"错误拼写为"piece"(同音),将"two"错误拼写为"too"(同音)。
拼写纠错
- Non-word拼写错误:任何不被词典包含的词都被视为拼写错误,识别准确率依赖于词典的规模和质量。
- Real-word拼写错误:每个词都作为拼写错误的候选,从发音和拼写等角度查找最接近的词集合作为拼写建议。
基于噪声信道模型的拼写纠错
噪声信道模型(Noisy Channel Model)是一个广泛应用于语音识别、拼写纠错、机器翻译等领域的模型。它试图通过带噪声的输出信号恢复输入信号,形式化定义如下:


应用于拼写纠错任务的流程如下:
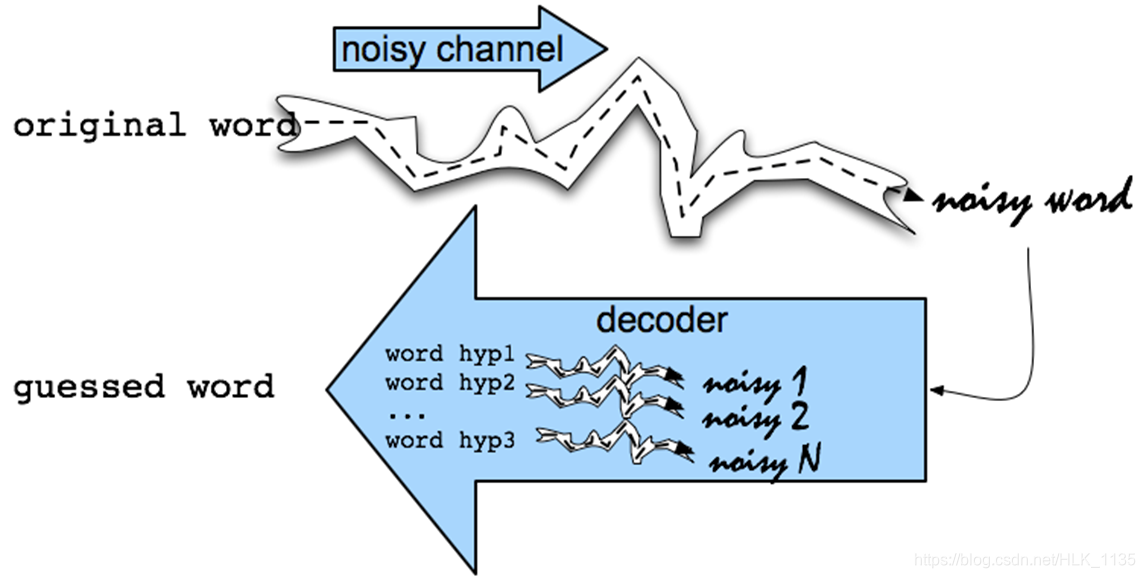
在拼写纠错中,我们将错误拼写的词(noisy word)视为通过噪声信道从原始词(original word)转换而来。现在,已知错误拼写的词(用x表示),我们的目标是找到最可能的原始词(用w表示)。公式如下:
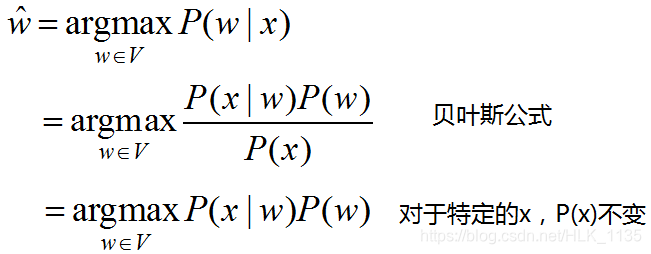
其中,P(w)为先验概率,P(x|w)为转移概率,二者都可以基于训练语料库建立语言模型和转移矩阵(error model,channel model)得到。
拼写检查器
拼写检查器的实现步骤如下:
- 以一个大型文本文件big.txt作为样本,分析每个单词出现的概率,构建语言模型(Language Model)和词典。
- 如果用户输入的单词不在词典中,则生成编辑距离(Edit Distance)为2的所有可能单词。
- 计算可能的拼写建议,并基于贝叶斯公式选择概率最大的词作为最终建议。
核心实现
以下是拼写检查器的核心
文章整理自互联网,只做测试使用。发布者:Lomu,转转请注明出处:https://www.it1024doc.com/4407.html